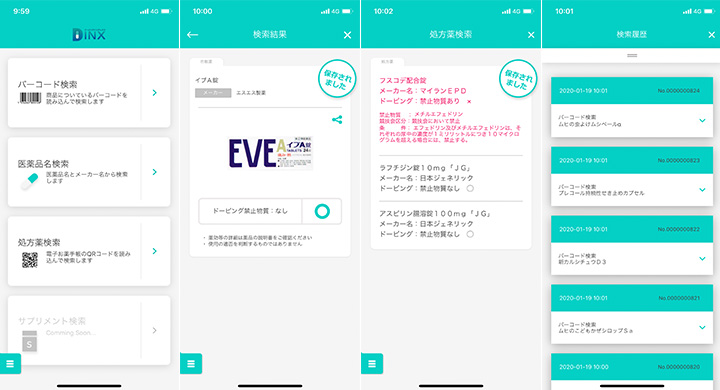
市販薬のバーコードをスキャンするだけで、禁止薬物が含まれているか否かがすぐに判明するドーピングインデックスアプリ『DINX』がリリースされた。医薬品名からの検索もでき、処方薬の場合は処方箋のQRコードを読み取るだけの便利なアプリ。そこで、サービスがリリースされた経緯や特徴について、開発者であるオンキヨースポーツ取締役の坂野道郎氏に訊いた。

国内の医薬品、ほぼすべてを網羅!
華やかなスポーツ大会の裏で、「ドーピング違反で出場停止」というニュースを目にする機会は多い。国家レベルで故意にドーピングをおこなっている例も聞くが、日本のアスリートは「うっかりドーピング」で処罰されるケースがほとんどだ。つまり、知らぬ間に禁止薬物を摂取してしまったということ。そのため、普段から体調が悪くても薬を飲まずに我慢しているアスリートも多い。
「チームドクターや栄養士はいても、ドーピングに精通しているスタッフがいることは稀です。その点では、日本は遅れているといえます」と語る坂野氏。
そこで、アスリート自らが簡単に市販薬や処方薬をチェックできるアプリ『DINX』を開発したというわけだ。

「DINXでは、医療用医薬品(処方薬)約2万品目、OTC医薬品(市販薬)約1万2000品目を超えるデータベースを使用しています。毎年元旦、WADA(世界アンチ・ドーピング機関)はドーピング物質の最新リストを発表するのですが、それに合わせて毎年更新していきます。そのため、毎年元旦から約2週間は検索ができなくなります」

ドラッグストアのPB(プライベートブランド)商品の一部は、成分情報を開示してないものもあり、「該当する医薬品情報は見つかりませんでした」の文言が表示されてしまうこともある。それ以外に関しては、日本国内で流通している医薬品のほぼすべてが網羅されているので使い勝手は抜群だ。
非故意証明書の発行もおこなう
また、『DINX』の魅力は豊富なデータベースだけではない。検索や結果履歴をデータで残すこと(最大10年間)で、「アプリを使って確認した後に摂取した」ことを証明する「非故意証明書」の発行を申請することができる。
「非故意証明書があれば裁判に勝てるというわけではありませんが、心象が良くなることは間違いありません」

年々厳しくなるドーピング検査
過去には、チームの20~30名が同じ薬を飲んでいたにも関わらず、ひとりだけがドーピング違反になった例もあったとか。その理由を調べたところ、同じ生産ラインで禁止物質を含む医薬品を生産しており、わずかながら混入してしまった錠剤があったとのこと。このケースの場合、さすがに『DINX』でも防ぎきれない。
それほどまでドーピング検査の精度は高く、ごくわずかでも違反者になってしまう怖さがある。また、故意でないことを証明するのは難しく、疑われた場合は窮地に陥ってしまうのは明確だ。一方で、かつては国体のベスト4くらいからの検査だったのが、近年はベスト8あたりからドーピング検査が実施されるなど、年々厳格化され始めている。
そんな状況を見越して、アスリートに寄り添ったサービスを提供している点は画期的だ。今のところ『DINX』は2020年9月6日までは無料で使用でき、その後は毎月低価格の課金制が予定されている。

現場で求められる機能を次々とアプリに実装中
開発者の坂野氏は、女子レスリングの強豪校で知られる至学館大学の「スポーツ栄養サポートチーム」の一員でもある。スポーツ栄養学の知見が高い同校は、これまでに数多くのチームやアスリートから相談が寄せられてきたという。しかし。すべてに対応することが難しいため、坂野氏はAIとアプリを使い、誰もが手軽に栄養を管理できる仕組みが作れないかと考えた。それが、オンキヨースポーツとして最初のサービスとなった、食トレアプリ『food coach』である。そのアプリと、GPSを含むGNSS(測位衛星システム)や、加速度/角速度センサーといった運動量測定デバイスとを連携させるサービス『KLOTO』も発表。ドーピングインデックスアプリ『DINX』は、第三弾のサービスとなる。
「『DINX』に関しては、東京オリンピックまでに英語版をローンチする予定です。これがあれば、海外の選手も日本の薬を安心して飲むことができますから」
どこまでもアスリートファーストな発想は、常に身近に選手たちを見守ってきたからの発想だ。現在は、時差の調整をスムーズにおこなうためのサービスを開発中とのこと。こちらはアスリートのみならず、出張の多いビジネスパーソンの需要も予想される。
なお、『DINX』で導き出される結果はあくまでもアスリート向けのものなので、もしドーピング物質を含む薬があったとしても一般の人にとって害は一切ない。そこはぜひ留意してほしいところだ。
DINX:https://dinx.pro/
坂野道郎(さかのみちろう)
オンキヨースポーツ株式会社 取締役。至学館大学 健康科学研究所 客員研究員。スポーツ栄養サポートチーム シニアアドバイザー。AIを使い、アスリートそれぞれに最適なスポーツ栄養をアドバイスするアプリ開発を着想。2017年、IBMの『Watson Build Challenge』
に同企画で応募したところ日本国内で優勝。それをきっかけに、オンキヨースポーツが立ち上がり、2018年に『food coach』をリリース。アスリートの育成・強化を目的としたサービスを開発し続けている。