スタイリッシュな映像で紹介されているのは、今やがん診断には欠かせない検査機器として日本でも広く普及が進んだGEヘルスケア・ジャパンが販売を手掛けているPET-CT検査機器「Discovery IQシリーズ」。販売開始から5年、新たに低被ばくをはじめとする、さまざまな高性能を搭載した「Discovery IQ 2.0」の販売を開始した。MotionFree (モーションフリー)、StressFree (ストレスフリー)、ArtifactFree (アーチファクトフリー) という3つのフリーを掲げ、現場従事者、患者双方にとって快適な検査を可能にしたようだ。
放射線を使った検査と聞いて、まず思い浮かべるのはX線撮影、通称 “レントゲン” だろう。健康診断やケガをした際などに、多くの方が経験したことがあるはずだ。レントゲンをはじめとする放射線を使う検査は、現代医療に不可欠な技術と言っても過言ではない。だが、わりと手軽な印象のレントゲンとは異なり、CTやPET-CT検査中には体の動きに制約を受けたり、検査に長時間を費やすこともあるため、検査を受ける側としては、ストレスになることもあった。撮影中は健康上全く問題無いと言われるほどのごく微量な線量ながらも、がんなどの治療中の患者であればとくに、毎回放射線を浴びることに対して一抹の不安を覚える人もいたことだろう。検査で生じるそんな患者の心配やストレスを解消するべく、同社が開発した検査機器では動きの制約を少なくし、放射線量もこれまで以上に抑えられているのだ。
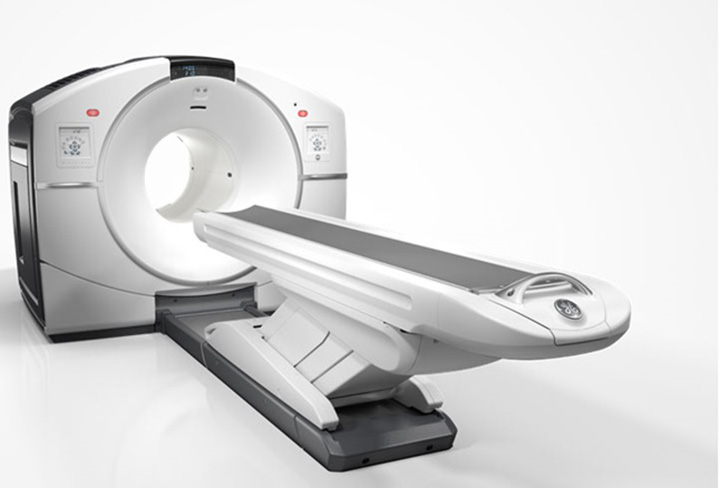
現在、がんを発見するための検査として非常に有効と言われているのが、PET-CT検査だ。
まずPET検査とは、がん細胞が正常な細胞と比べてブドウ糖を多く必要とするという性質に着目したもの。ブドウ糖に、ごく微量の放射線を放出する成分をくっつけた薬剤 (以下、FDG) を体内に注射し、検出器というカメラのような装置を用いて、FDGの全身への分布状態を撮影する。がん細胞にはFDGが正常な細胞よりたくさん集まるため、そこから放出される微量の放射線を検出器でとらえて、がん細胞の位置や大きさ、進行度合いを調べるという仕組みだ。PET-CT検査は、このPET検査にCT検査 (X線を体の周囲から照射して断面図を作る検査) を組み合わせたもの。さらに克明に病気の状態を探ることができる点が特徴だ。
がんの発見に優れた力を発揮するPET-CT検査だが、放射性物質を含んだ薬剤を体内に取り入れるうえにCT検査による放射線照射も行うため、PET検査と比較すると当然被ばく量は多くなる。そのため、患者だけでなく、患者を介助する現場従事者にも微量ながら被ばくのリスクが発生する。さまざまな医療機関や研究団体が、医療検査による被ばくは健康に影響を及ぼす量ではないと発表しているものの、当事者の心理としては、たとえ微量だとしても懸念があるというのが正直なところではないだろうか。
今回リリースされた「Discovery IQ 2.0」は、低被ばく、高速ワークフロー、高画質化を実現したPET-CT検査機器。まず注目したいのは、超高感度で幅の広い検出器の搭載。これにより、検査時間の短縮が可能となる。従来、PET-CT検査に要する検査時間は受付から検査終了まで3~4時間を要するものとされていたが、当機器を使用する場合、検査時間は最大10%削減されるという。
検査時間の短縮自体が現場従事者と患者のストレス低減になることはもちろん、高感度検出器の搭載によるFDG投与量の減少と併せて、低被ばく化にもつながる。具体的には、現場従事者の被ばく量は1ヶ月あたり2時間分の低減が見込まれている。操作室で遠隔での操作が可能となったことで、現場従事者が患者と接触することによる被ばくのリスクを抑えられる点もメリットのひとつだ。
また、業界初となる患者の呼吸による動きを自動補正するシステムを採用することで、画像のブレを低減するシステムを搭載。従来の検査では、呼吸によるブレを防ぐために、患者が一時的な息止めなど意識的に呼吸をコントロールするケースもあったが、そのような検査時のストレスを低減することができる。
さらに、従来の画像再構成法ではできなかった、「画質」と「定量精度」 双方の向上を実現。ノイズの多くなりやすい部位でもクリアな画質を実現するため、診断精度が飛躍的に向上した。
ただでさえ億劫になりがちな病院での検査。せめてなんのストレスも懸念もなく受診したいと思うもの。「Discovery IQ 2.0」はそんな気持ちに寄り添った、まさにストレスフリーな最新技術だ。
[TOP動画引用元:https://www.youtube.com/watch?v=mNOrlphDaf4]